Reimplementing the Topics API classifier
Yohan Beugin - February 2024
In this post, I discuss my research needs to reimplement the Topics API for the web and so, explain how the classification in Chrome is actually performed by presenting all pre- and post-processing steps used by Google. I also point at a formatting issue that I found along the way that impacts the intended accuracy of the API classification for some domains.
Research needs
As part of my research ([1] and [2]) on the privacy and utility guarantees of the Topics API for the web, I need to classify thousands of different inputs with the Topics API.
If the internal page chrome://topics-internals/ on
Chrome does let you use the classifier implemented by Google, it
is only useful for a few domains in practice and does not meet my
needs when scaling up. Not to mention the impossibility to access
the raw classification results and/or bypass the pre- and
post-filtering steps of the machine learning model (all useful for
more detailed analyses of the API).
Google engineers also released a demo of the model execution for the web API. While this demonstrates how to extract the override list from the protobuf file and run some inferences on the Tensorflow Lite model –both respectively shipped with Chrome– this Jupyter notebook does not cover all the pre- and post-processing steps applied in the classification deployed in Chrome. This can easily be verified by checking that the classification results of the demo disagree with the ones from Chrome’s internal page.
Only one path forward remains: it is time to dive into Chromium source code, find Google’s implementation of the Topics API, and reimplement it in a way that suit my needs.
The Topics API for the web classifier
Overview
With the Topics API, web users’ behaviors are classified into topics of interest from a fixed taxonomy of topics. This is done in 2 steps; first the websites visited by users during each epoch are classified by the API into topics, and then only the top topics of that epoch for each user get saved to be returned to advertisers. In this post, we focus on the first part: the classification of websites into topics (top section of the figure).
The FQDNs of visited websites are pre-processed and checked against a list of domains mapped to topics that was annotated by Google. If it is not present in that override list, the domain is classified by an ML model whose output gets filtered before the final mapping gets returned.
Pre-processing and override list (static mapping)
The Topics API for the web considers that its input is composed
of FQDNs, the pre-processing that is applied, first removes any
"www."prefix if present in the domain to classify,
and then replaces the following characters
"-", "_", ".", "+" by a whitespace. This
pre-processed domain is then checked against the override list to
see if its mapping is known. Otherwise, the ML model is executed
to infer its topics.
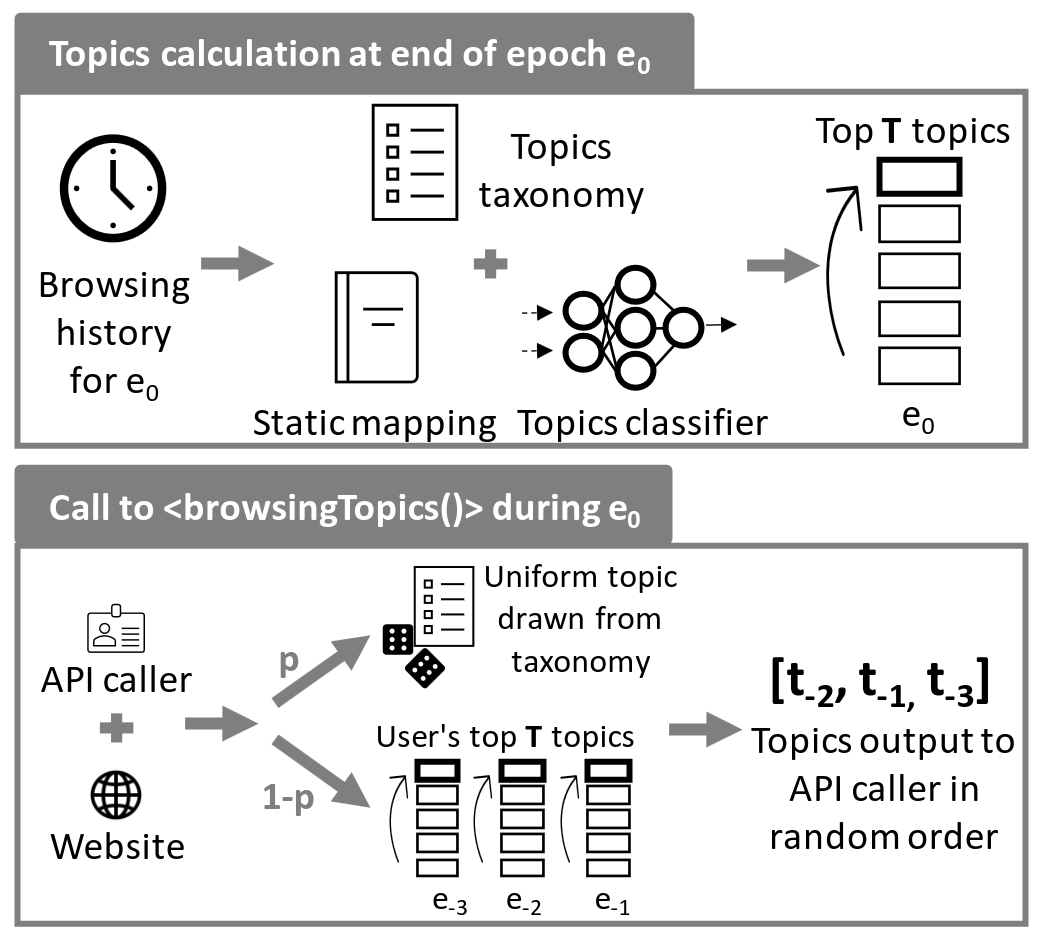
Post filtering of the ML model
The ML model outputs as many confidence scores as there are topics in the corresponding taxonomy; i.e., 1 score for each topic. As of February 2024, these scores are filtered the following way (see algorithm also):
- the top 5 scores ordered by their confidence scores are kept
- the sum of these 5 scores is computed and any topic with a score lower than 0.01 is discarded
- if the
"unknown"topics is still present and if its score contributes to more than 80% to the previous sum of 5 scores, then only the"unknown"topic is returned - if the contribution is lower, the
"unknown"topic is discarded and the remaining scores are normalized by the total sum previously computed - any topic with a normalized score higher than 0.25 is output
- if after all these steps, no topic was output at all, the
"unknown"topic is returned
Reimplementation
My reimplementation can be found here: https://github.com/yohhaan/topics_classifier

Formatting issue in the override list
Google ships with Chrome an override list, which is a mapping manually annotated by Google of domains to their corresponding topics. When a domain is being classified by the Topics API, it is checked against that list first and if not found classified by the ML model.
The override list shipped in Chrome with the 4th version of the
Topics model contains 47 128 such individual mappings from domains
to topics. However, it appears that 625 of them are not formatted
correctly as they contain the "/" invalid character
(according to the pre-processing rules applied to the input) and
are flipped around that invalid character. As a result, when
trying to classify the corresponding initial domain by applying
the pre-processing to the input domain, no match is found in the
override list. Thus, the ML model is used for the classification
and different results than the manual annotations are output.
Let’s illustrate this with a few examples:
| Input domain | Pre-processed domain | Chrome classification (calling the ML model) |
Override list entry (note the / invalid character)
|
|---|---|---|---|
| candy-crush-soda-saga.web.app | candy crush soda saga web app |
183 Computer & video games 186 Casual games 1 Arts & entertainment |
web app/candy crush soda saga186 Casual games 215 Internet & telecom |
| subscribe.free.fr | subscribe free fr | 217 Internet service providers (ISPs) |
free fr/subscribe 217 Internet service providers (ISPs) 365 Movie & TV streaming 129 Consumer electronics 218 Phone service providers |
| uk.instructure.com | uk instructure com |
229 Colleges & universities 227 Education |
instructure com/uk 230 Distance learning 234 Standardized & admissions tests 140 Software 227 Education 229 Colleges & universities |
The list of 625 domains with an incorrect character is available here. You can reproduce that list following these instructions.